In this post I share the latest in my quest for continuous learning. This time, I experimented with the Pipeline class by scikit learn to see on its advantages. I applied it to a machine learning task that I previously worked on, churn prediction.
From my reading, using Pipeline is supposed to be simple, yet a powerful way of designing sophisticated machine learning systems [source]. I had not come across many analysts that use it (though now after searching for it, I have come across more examples where its used). The class is set up with the fit/transform/predict functionality, similarly to other estimator classes like LinearRegression. One of the advantages is that you can fit a whole pipeline to the training data and transform to the test data [source]. This means that, you do not need to carry out test dataset transformation if you already did it with your train features – this is taken care of automatically [source]. Hyperparameter tuning is also made easy, new parameters can be set on any estimator in the pipeline and refit – all in one line. Its also easy to use GridSearchCV on the pipeline to find the best parameters [source].
Below I run through the exercise I did where I used Pipeline, Logistic Regression, Standar Scaler, Principal Component Analysis, and GridSearchCV for churn prediction. Code is also available on github. I make use of the telco-churn dataset available here.
First I loaded the necessary libraries, dataset, nothing special there. I then did a bit of data exploration, looking at missing values, distribution of the target class, removing irrelevant data, and changing data types. Normally I would do more data cleaning and exploration, but that was not the point of this exercise.
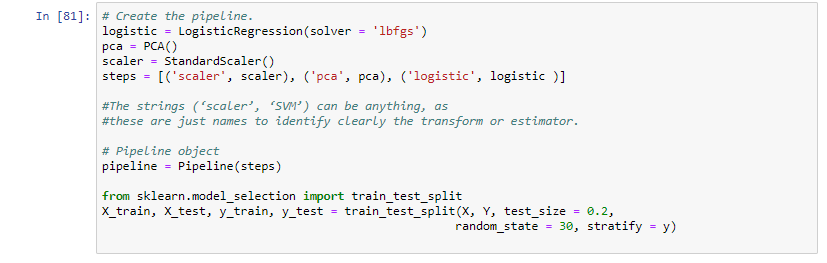
As seen in the next steps, the pipeline object is created by providing a list of steps. The steps are a list of tuples consisting of a name and an instance of the transformer or estimator that are chained, in the order in which they are chained. The names can be anything, but the final item in the tuple list should be an estimator. In this exercise, I provided Standard Scalar, Principal Component Analysis, and Logistic Regression as the steps.

Doing grid search over this is also quiet easy.

And then do the predictions.

From this small exercise, I find that using the Pipeline class provides convenience in that you do not have to apply fit and transform methods twice, i.e., to the train and test sets. Its also easy to read. In addition, as mentioned also by [source], it “enforces a desired order of application steps which in turn helps in reproducibility and creating a convenient work-flow.” Will probably start using it more often in my work.